Clearing the Air
Oct 31 2019 | By Allison Elliott | McNeill Photo Credit: John Abbott | Kolkata Photo Courtesy of V. Faye McNeill
Imagine a world where data could be controlled, secured, and even shared without comprising personal privacy

Roxana Geambasu
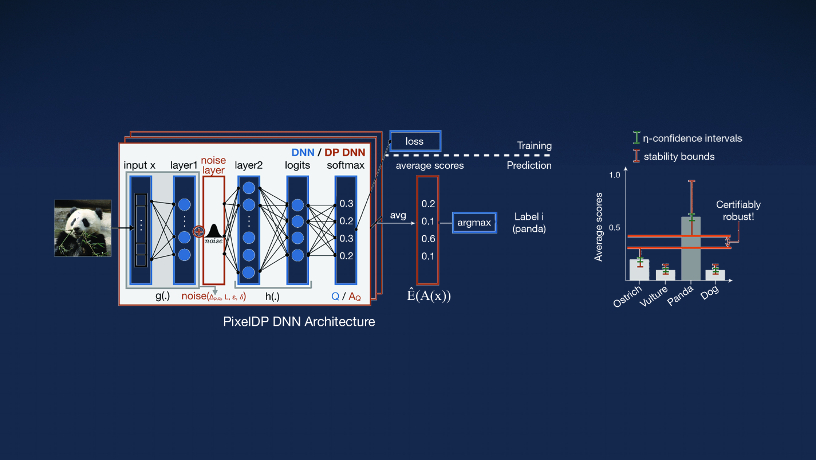
Design of a deep neural network that provides a guaranteed level of security against adversarial perturbation attacks.
The rise of machine learning (ML) is ushering in transformative applications from self-driving cars to personalized medicine. But its dependence on massive data sets opens up unintended vulnerabilities—once adversarial actors gain access to information embedded in training data, they can reconstruct original inputs, including medical results and financial information.
“The problem is artificial intelligence and machine learning, and similar technologies, are extremely data hungry,” says Roxana Geambasu, associate professor of computer science. “They drive companies to aggressive data collection, some of which is very sensitive.”
An expert in data security, privacy, and transparency, Geambasu develops tools and adapts proven practices to build systems for this ever-evolving landscape, where privileging user privacy can lead to better strategies for promoting data security.
Her elegant solution: take an already existing technology and leverage it in novel ways for ML applications. That tool—known as differential privacy (DP)—is used to add statistical noise to computations on data sets so that any given individual’s information contained within cannot be de-anonymized from the aggregate.
In many circumstances, however, deploying DP leads to operational challenges that compromise the precision of the model. To resolve those issues, Geambasu created SAGE, a platform that preserves accuracy while enforcing DP across all ML models fed by sensitive data streams. For instance, SAGE incorporates a unique method of transforming data streams into fixed-timeframe blocks that are retired if they reach a predetermined upper limit for privacy loss.
Currently, Geambasu is applying her methodology to ML models trained on clinical data and public FDA data sets as part of a collaboration with Columbia’s medical school (P&S) and NewYork-Presbyterian Hospital. Using her system, biomedical researchers can gain access to a narrowly tailored set of previously protected data that paints a fuller picture of side effects and symptoms associated with certain health conditions—the kind of information that could lead to better research findings and ultimately better diagnosis and treatment strategies.
“There are good reasons to share data, but what to share—that is the question,” Geambasu says. “If you’re willing to only share models, we know how to secure those with mathematical guarantees.”