Tony Jebara
Data Science
Creating Intelligent Machines
In our age of information overload, Tony Jebara, associate professor of computer science, is working to help make sense of it all. Armed with a keen sense of order and a penchant for applying the rigor of mathematics to solve problems, he is helping machines seamlessly integrate and organize loads of data for us.

The Father of Big Data
Herman Hollerith
Alumnus
Before computer giant IBM became a household name, there was Herman Hollerith’s technological breakthrough that automated a once manual, time-consuming system to count mountains of data. After graduation, Hollerith, Class of 1879, worked as a statistician at the 1880 U.S. Census Bureau. Before long, he was convinced there had to be a better, faster way to tabulate the huge amounts of data being collected and recorded by hand. His answer: punch cards and an electric tabulating machine, which was ultimately used to calculate the 1890 census.
Data was recorded by punching holes in cards of nonconducting paper and then tallying these by mechanical counters operated by electromagnets. Hollerith developed a hand-fed press that sensed the holes in the punched cards; a pin wire would pass through the holes into a container of mercury beneath the card, closing the electrical circuit. This process triggered mechanical counters and sorter bins and tabulated the appropriate data, allowing the census information to be tallied in a remarkably quick six months.
Hollerith (1860–1929), who was just 19 when he completed his Engineer of Mines degree at the School, produced many other innovative models of the original tabulating machine and sorter. He also invented the first automatic card-feed mechanism and the first key punch, in addition to other patents on railroad brakes and corrugated metal tubing.
An early player in computer information systems long before the words “big data” became a go-to buzzword in mainstream media, Hollerith was also one of the School’s first alumni entrepreneurs. After his success in revolutionizing the 1890 census, Hollerith founded a start-up based on what quickly evolved into a booming business in electric counting machines. His company, the Tabulating Machine Company, was one of the four companies that merged to form the Computing-Tabulating-Recording Company (C-T-R). In 1924, C-T-R changed its name to IBM.
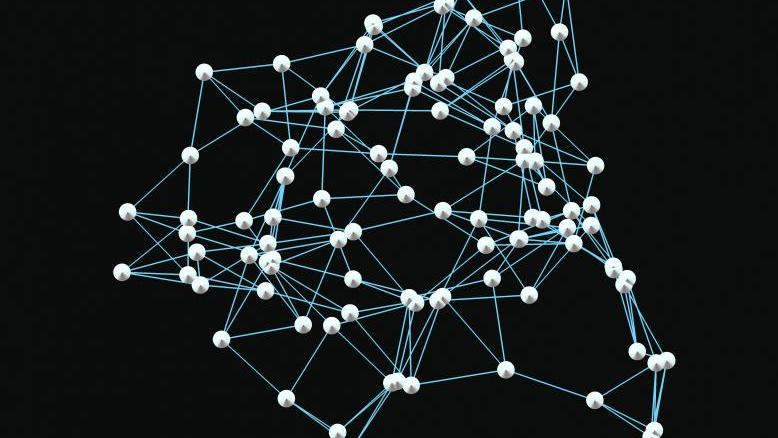
Tony Jebara’s b-matching and minimum volume embedding algorithms are applied to visualize the scholarly works of more than 100 researchers affiliated with Columbia’s Institute for Data Sciences and Engineering. Each researcher is represented as a point. Researchers who use similar word-frequencies in their publications are placed near one another.
Specializing in the science of machine learning, Jebara studies the fundamental principles of learning, combines statistics and computer science, and develops algorithms that inform the programming that allows computers to learn rules from data, adapt to changes, and improve performance with experience. These intelligent machines impact everyday life in ways most people take for granted, such as web search and spam filters, fraud detection and stock purchasing, and parallel parking without driver intervention.
“Machine learning and data science are really about finding the right blend of computational and statistical thinking,” Jebara says. “It’s a creative challenge with questions of how to map real-world problems into mathematical, statistical, and computational terms.”
Jebara’s work builds on a foundation constructed by a 19th-century alumnus of the Engineering School, Herman Hollerith, who is widely regarded as the father of modern automatic computation. A statistician, Hollerith developed an electric tabulating system used in processing census data punched on cards for the 1890 federal census. Hollerith’s designs dominated the computing landscape for almost 100 years. His Tabulating Machine Company merged with the Computer Tabulating Recording Company, which was later renamed International Business Machines Corporation, better known today as IBM.
“Hollerith was the great-grandfather of computational statistics,” Jebara says. “More than a century ago, he brought computational and statistical thinking together to create the framework for modern-day study about machine learning and big data.”
In his day, Hollerith tackled the complexity of gathering and tallying data and revolutionized computation. Jebara is likewise focused on modern-day classification of computational problems based on their inherent difficulty. He is currently focusing on approximately solving problems in the NP-hard (nondeterministic polynomial-time hard) complexity class. By pioneering new computer learning techniques, Jebara is making significant breakthroughs that will help computers manage NP-hard computational decision problems, search problems, or optimization problems that require verifiable proofs, such as recognition of hand-written text, extraction of information from images, automatic translation of language, prediction of shopping behavior, or identification of genes that might be related to a particular disease.
“For a long time, we had proofs that many machine learning problems were NP-hard and therefore there was no hope of ever solving them well and efficiently,” Jebara explains. “However, we are now realizing that the worst-case situations where NP-hardness is an issue are unlikely to occur in nature. So, by creating algorithms that avoid these degenerate settings, we can essentially solve the challenges optimally for a large class of important problems.”
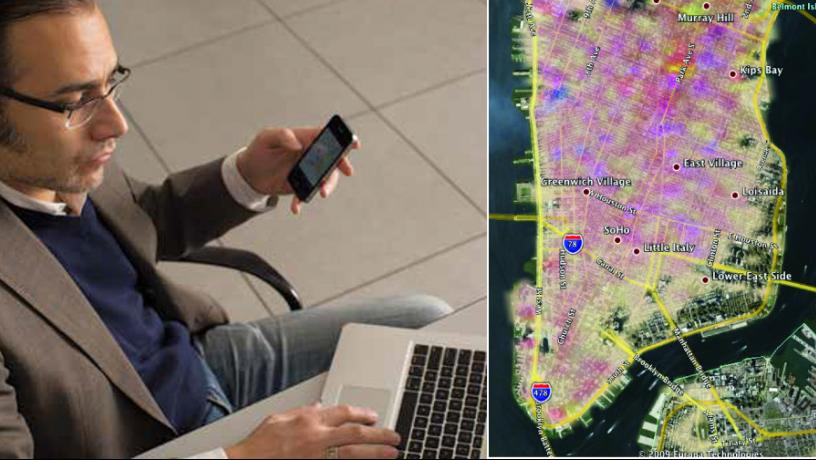
A visualization of movement patterns from GPS location data in New York City—Jebara’s algorithms color code city blocks to indicate which places attract similar crowds.
Statistics is a very powerful language, but if a researcher just considers statistical issues without worrying about underlying mathematics and computational efficiencies, the real-world application of their work will be drastically limited.
Jebara has parlayed his research in machine learning into an entrepreneurial focus to impact real-world problem solving. He has founded and advised several start-ups that employ his algorithms to develop software for web and mobile applications. Among his business successes is the company Sense Networks, which created apps that compile real-time mobile location data and usage patterns to make recommendations for its users as well as more targeted advertising. Other ventures have employed Jebara’s research to create mobile personal assistant software, all-in-one vacation rental software, and marketing tools used in the hospitality industry.
Harnessing that entrepreneurial spirit, Jebara was appointed chair of the Center for the Foundations of Data Science within the University’s Institute for Data Sciences and Engineering. Under his direction, the Center’s research focus is on formal and mathematical models for data processing, as well as on issues concerning the engineering of large-scale data processing systems. The Center has a twofold deliverable: lead in translational research and in education through a collaborative effort in engineering, computation, and statistics. For Jebara, that’s a mission he has perfected.
“Through machine learning, we first collect massive amounts of diverse data. And then we computationally and statistically explore a massive number of potential hypotheses against that large data to find truth,” he says. “Statistics is a very powerful language, but if a researcher just considers statistical issues without worrying about underlying mathematics and computational efficiencies, the real-world application of their work will be drastically limited.”