What Machines Can Learn from Genes
AI gives researchers fresh insights into treating cancer, predicting neurodegeneration, and monitoring the microbiome

David Arthur Knowles, assistant professor of computer science.

Elham Azizi, assistant professor of biomedical engineering.

Itsik Pe’er, associate professor of computer science and systems biology.
Often one medical treatment won’t work in every case. Different patients inhabit different bodies, environments, and lifestyles, a diversity that has given rise to precision medicine. Genetic sequencing of healthy cells, tumors, or bacteria, combined with new tools in artificial intelligence, are giving researchers fresh insights into the causal connections between genes and neurodegeneration, cancer, and the microbiome, information that could lead to better treatments all around.
For decades, scientists have known that a person’s genetic makeup plays a significant role in triggering neurodegenerative diseases like Alzheimer’s. What no one has been able to precisely determine is which genes are involved and how they go awry. Traditional statistical genetics methods can predict neurodegeneration using whole genomes but tell researchers little about the genes and molecular mechanisms involved. David Arthur Knowles, assistant professor of computer science, leverages transcriptomics—measurements of genes that are transcribed into RNA before RNA manufactures proteins— using deep neural networks adapted from the world of computer vision to predict gene expression based on DNA sequence. The networks simulate the effects of genetic changes, then that information is fed into a Bayesian statistical model that attempts to answer the question, Which genetic differences, genes, and cell types are responsible for Alzheimer’s disease?
Genome sequencing technology is advancing rapidly. The first human genome, completed in 2003, cost nearly $3 billion. Today, sequencing a human genome costs less than $1,000, with targeted approaches costing even less. “That makes it a very exciting space for computational people to work in,” Knowles says, “because there’s both a lot of data and new data types all the time. That keeps us very busy.”
One reason cancer has proven to be such a formidable foe is the stunning complexity of the disease, not just in how each tumor differs from every other but also in how many widely divergent cell types operate within each tumor. If doctors could tease out both a tumor’s composition and what that says about its expected development, they might target particular malignant cells better, for example. Elham Azizi, assistant professor of biomedical engineering, leverages both genetic and imaging data to probe that heterogeneity. By exploring how populations of cell types within a tumor change (by comparing biopsies before and after a treatment), Azizi is zeroing in on strategies for revealing how therapies do what they do. Preliminary findings revealed that unexpected cell types, such as bone marrow progenitor T cells, proliferated after a treatment. By searching for patterns on its own, machine learning can quickly test hypotheses about which treatments might produce desired results in specific instances. “And that allows us to find these needles in haystacks that could have been overlooked with more biased studies,” Azizi says.
Like Knowles, Azizi uses Bayesian models—which are more interpretable, can quantify uncertainty, and can flexibly integrate different types of data—while using neural networks to handle large volumes of raw data. Combined, the approaches let Azizi effectively interpret patient data without first running carefully controlled experiments on mice or cell cultures to know what to look for. “We directly start with the more complex problem in patients,” she says, “and use machine learning to tackle the complexity.”
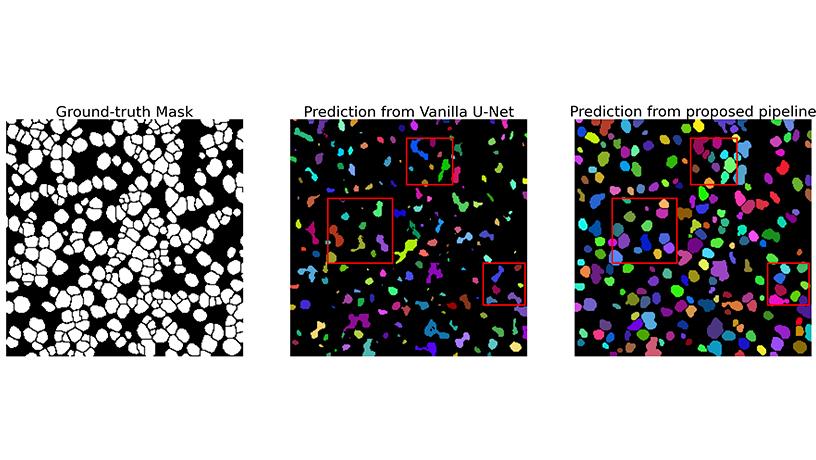
Improved segmentation of breast tumor cells using a neural network framework with the incorporation of geometric priors.

Representation of main tasks of continuous process of scientific discovery for microbiome research.
Genes can clearly cause disease. With your microbiome, the bacteria population that outnumbers the human cells in your body, causality is even more convoluted because bugs and other cells influence each other. That makes microbiomes particularly hard to study. “But on the flip side, they are rewardingly malleable,” says Itsik Pe’er, associate professor of computer science and systems biology. “You’re born with your genetics, but you can clinically interfere with and change a community of bacteria.” He collaborates with different labs gathering microbial data from leukemia patients, liver transplant recipients, and people with Crohn’s disease.
Doctors and researchers sometimes analyze bacterial population dynamics by taking stool samples at multiple times. But that’s not always possible. Pe’er has developed a way to measure the rate of change from a single snapshot, similar to how a blurry runner in a photo indicates movement. Knowing how fast bacteria replicate and where on the genome that process starts, he can detect population change based on how many genetic fragments he finds from different parts of a bacterium’s genome. If a population is small but growing quickly, a clinician might want to take note.
“AI has turned out to be a super important paradigm for biomedical investigation,” Pe’er says. Any measurement gives only an inexact picture of the underlying biology, and biology is stochastic, with random perturbations often throwing the whole system off. “Modern AI is really based on exactly that premise,” he says. Machine learning brings into focus fuzzy patterns and probability.